【导读】神经语义解析往往需要先人工设计一种中间过程来约束逻辑表达式的生成过程。能否让模型适应不同的目标,减少人工设计的工作量?最近,来自中科院自动化所NLPR的自然语言处理团队研究人员提出一种使用不确定性驱动自适应解码方法,来自动确定模型的困难程度。此论文已被ACL-2019接收。
AdaNSP: Uncertainty-driven Adaptive Decoding in Neural Semantic Parsing
作者:Xiang Zhang,Shizhu He,Kang Liu,Jun Zhao
【动机与目标】
神经语义解析是用神经网络来解析自然语言句子,并输出与句子语义相同的逻辑表达式的过程。最早的神经网络方法将此任务看做是一个序列到序列的变换,从而使用Seq2Seq方法。但是,逻辑表达式是一种形式语言,有非常严格的语法和语义要求。而神经网络主要由数据驱动,为了 保证语法和语义正确,往往需要补充大量数据,这是不现实的。
近年来提出了大量的解码器约束方法,以便解码器输出的序列是一个合法的逻辑表达式。这些方法主要包括基于梗概(Sketch)、基于过渡(Transition-based)、以及基于子模块等方法,使用神经网络来描述逻辑表达式的生成过程。例如梗概的方法先设计了一个中间表达,得到中间表达后再按照要求,补全指定数目的后续符号,从而得到最终结果。而基于过渡的方法需要定义一系列动作或语法产生式规则,解码器输出这些规则步骤,依次使用这些步骤规约即可得到最终结果。基于子模块的方法将目标语言的不同部分(例如SQL的不同子句)由不同的网络模块输出,再组合出最终的逻辑表达式。
然而,这些方法需要针对每一种具体的逻辑表达式,人工地设计一种中间表示。考虑到领域特定语言(Domain-SpecificLanguage)在不同领域上有各自的不同设计,并且领域专家的知识也可能不够完整,因此这种由人工设计中间语言的研究方法对新的领域提出了很高的要求,难以迁移到不同类型的逻辑表达式上。
针对这一难题,我们借助了自适应计算的方法。对于数据集中较为常见、容易解码的符号,模型可以毫不费力地输出。但是对于较为少见、模型不太确信的符号,我们让模型自适应地借助更深的网络进行多步计算,再进行输出。这种方法避免了基于梗概、过渡等方式对于人工设计中间语言的要求。为了训练自适应模块,我们使用不确定性作为奖赏信号,如果当前输出的不确定性估计较大,则模型自动执行更多深层网络的计算。
【方法】
(1)模型框架
我们使用了神经网络中常见的编码器-解码器框架。其中,为了与已有工作保持可比性,我们在编码器部分使用了自动训练的词向量和标准的双向LSTM网络结构。
解码器部分我们使用层叠的LSTM作为循环单元。并且加入了对于编码器输出和已有的解码器输出的关注机制。解码器的输入包括了词汇、关注向量以及一个flag输入。在第一层此flag为0,在深层计算时此flag为1。如式(1)所示
给定一个输出状态s,我们使用一个停机模块来决定此时刻的符号是否需要结束。停机模块输出一个与模型的不确定性正相关的停机概率,我们从该概率定义的伯努利分布中进行采样,得到一个深度计算的决策。若决策为1,则模型重新使用(1)式进一步得到一个新的状态,若决策为0,则该输出状态s将输出给词表预测模块,得到最终的符号。我们设置了一个深度计算的上限为3次,即重复计算3次之后无论模型是否确信,都将该状态用于输出。图1展示了我们模型的整体结构。
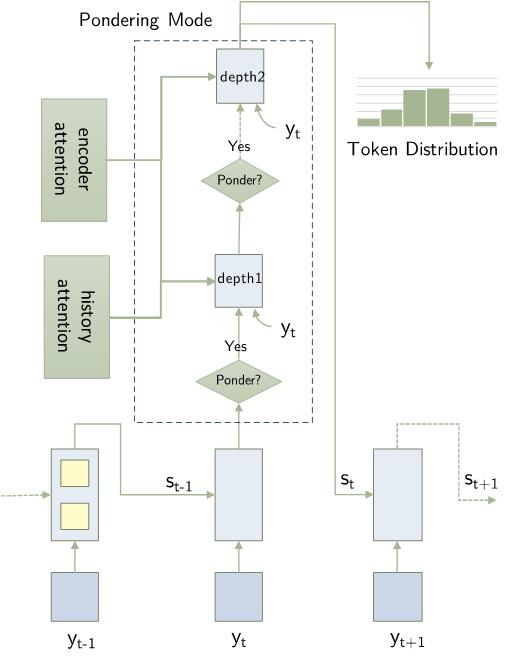
图1:使用不确定性驱动的自适应解码模块示意图
(2)不确定性驱动训练
为了帮助输出模块进行训练,我们使用Dropout作为一个简单有效的不确定性信号。我们将模型置于“训练”模式,但禁止了梯度的传播,这样每次输出受Dropout影响会得到不同结果,但并不会影响模型训练的梯度。通过执行F次(1)式以及后续的符号预测,我们得到F个标准符号的预测概率。这F个概率值的方差即可作为模型此时的不确定性的一个估计值u。我们将估计值u归一到[0,1)区间内。
我们使用了REINFORCE算法来训练停机模块。模型的动作空间是{继续,退出},每次的决策为二选一。若模型选择继续,且当前的预测输出错误时,模型的奖赏值为不确定性估计值u;若模型选择停止,且当前的预测输出正确,则模型的奖赏值为1-u;其他情况下模型的奖赏值为0。对于编码器和解码器部分,我们使用标准的交叉熵损失进行训练。
【实验】
我们使用公开的预处理后的ATIS和GeoQuery数据集进行实验。这两个数据集的输出为lambda表达式,对于输出结果我们将其解析为树结构,并衡量输出和标准的结构是否相同,以保证树的孩子之间的顺序不影响结果。
实验表明,我们的方法不仅避免了人工设计中间表示,且性能达到或超过了目前需要手工设计中间表示的模型。而当移除停机模块之后,模型退化为普通的Seq2Seq结构,性能比我们提出的标准模型在两个数据集上分别下降了2.8和2.9个百分点,这说明了使用停机模块进行自适应计算的有效性。

【结论】
我们提出了针对神经语义解析的自适应解码器,该解码器由模型的不确定性进行训练。我们的模型不需要使用人工定义中间步骤,而是通过自适应的方式调整模型输出的计算深度。实验证明,这种用不确定性来动态调整网络结构的方式取得了比需要手工设计中间表示的模型相当或者更好的效果。
论文链接:https://www.aclweb.org/anthology/P19-1418/
【参考文献】
[1]. Bo Chen, Le Sun, and Xianpei Han. 2018. Sequence-to-action: End-to-end semantic graph generation for semantic parsing. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1:766–777.
[2]. Li Dong and Mirella Lapata. 2018. Coarse-to-fine decoding for neural semantic parsing. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1:731–742.
[3]. Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning, page 1050–1059.
[4]. Alex Graves. 2016. Adaptive computation time for recurrent neural networks. arXiv:1603.08983 [cs]. ArXiv: 1603.08983.
[5]. Pengcheng Yin and Graham Neubig. 2018. Tranx: A transition-based neural abstract syntax parser for semantic parsing and code generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, page 7–12. Association for Computational Linguistics.
|