Social Event Classification via Boosted Multimodal Supervised Latent Dirichlet Allocation
Shengsheng Qian, Tianzhu Zhang , Changsheng Xu and M. SHAMIM HOSSAIN
Summary

With the rapidly increasing popularity of social media sites (e.g., Flickr, YouTube, and Facebook), it is convenient for users to share their own comments on many social events, which successfully facilitates social event generation, sharing and propagation and results in a large amount of user-contributed media data (e.g., images, videos, and text) for a wide variety of real-world events of different types and scales. As a consequence, it has become more and more difficult to exactly find the interesting events from massive social media data, which is useful to browse, search and monitor social events by users or governments. To deal with these issues, we propose a novel boosted multimodal supervised Latent Dirichlet Allocation (BMM-SLDA) for social event classification by integrating a supervised topic model, denoted as multi-modal supervised Latent Dirichlet Allocation (mm-SLDA), in the boosting framework. Our proposed BMM-SLDA has a number of advantages. (1) Our mm-SLDA can effectively exploit the multimodality and the multiclass property of social events jointly, and make use of the supervised category label information to classify multiclass social event directly. (2) It is suitable for large-scale data analysis by utilizing boosting weighted sampling strategy to iteratively select a small subset of data to efficiently train the corresponding topic models. (3) It effectively exploits social event structure by the document weight distribution with classification error and can iteratively learn new topic model to correct the previously misclassified event documents. We evaluate our BMM-SLDA on a real world dataset and show extensive experimental results, which demonstrate that our model outperforms state-of-the-art methods.
Framework
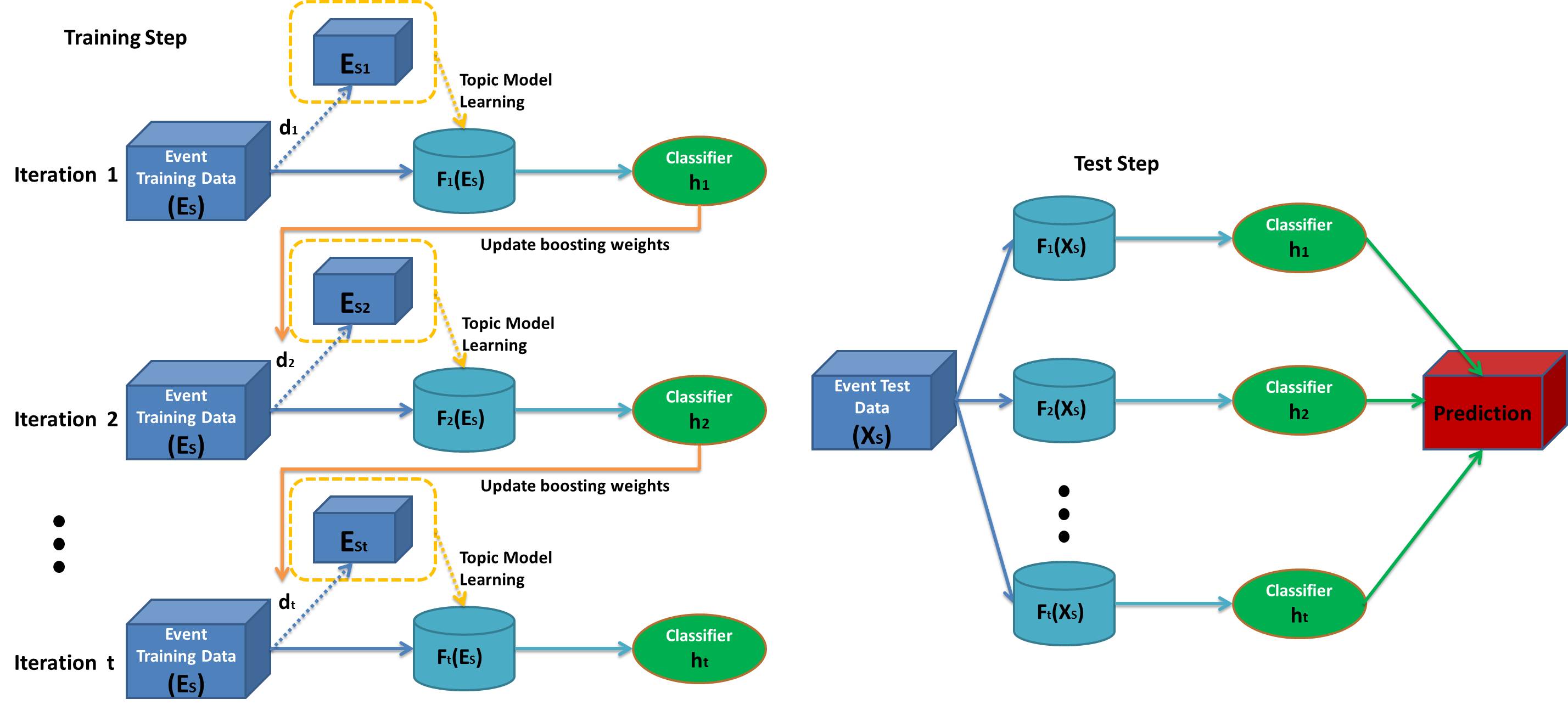
Figure 2: The flowchart of the training and test process of our proposed BMM-SLDA model for social event classification.
We propose a novel boosted multimodal supervised latent dirichlet allocation (BMM-SLDA) algorithm to iteratively obtain multiple classifiers for social event classification. The basic idea is to integrate a supervised topic model process in the boosting framework. Each iteration of boosting begins to select a small part of documents from large-scale training data according to their weights assigned by the previous boosting step. Based on the sampled small subset of data, the proposed mm-SLDA is applied to learn the corresponding topic model. In mm-SLDA training process, it can capture the visual and textual topics across multimodal social event data jointly and directly utilize the supervised event category information for social event classification modeling, which is implemented by considering the class label response to variable drawn from a softmax regression function. The resulting topic model is then applied to learn a new classifier. Based on the learned classifier, the documents in the training data are classified to obtain the classification scores. Finally, the new weights of documents in training data are updated by the use of the classification scores. Based on the above procedure, it is clear that the documents are iteratively reused with different weights to learn multiple topicmodels to build a strong social event classifier. In a word, our algorithm has two steps. Figure 2 shows the main steps of the proposed algorithm. In the training step, we iteratively learn multiple topic models based on the selected documents from the training data, and obtain the corresponding weak classifiers. In the testing step, the documents are described by the learned topic models and classified with the combination of the corresponding weak classifiers to determine their final class labels.
Boosted Multi-Modal Supervised Latent Dirichlet Allocation

As shown in Algorithm 1, it gives the details of the training step of the proposed BMM-SLDA algorithm.
In the training step, multiple topic models are learned inside a boosting procedure with different training documents.
In each iteration , we sample a subset
from the whole training
document set
according to
their weights
assigned by the previous boosting
iteration.
This subset
is then used as a guide to
learn the corresponding topic model parameters
as introduced in the Figure 3.
Then, the learned parameters are
applied to learn a new weak learner
.
Based on the classifier, the documents
are classified
to obtain their classification errors
.
Finally, the new weights of documents are updated
by using the classification error
.

Figure 3: The proposed multimodal supervised Latent Dirichlet Allocation topic model for social event classification.
Based on the sampled subset at the
-th iteration, we deal with the
social event classification problem via mm-SLDA model, which can make use of
the event multi-modal property and the event category information jointly to learn an effective and discriminative event model.
The proposed model has the graphical representation as shown in the Figure 3.
From the figure, we can see that our model can mine the visual and textual topics of different social events together by considering the supervised label information.
Results
We show extensive experimental results on our collected dataset to demonstrate the effectiveness of our model.
A. Qualitative Evaluation:

Figure 4: The discovered topics by our proposed BMM-SLDA. Here, we show six topics with their top five textual words and the five most related images.
We demonstrate the effectiveness of our BMM-SLDAmodel on themining of social events and show the discovered topics in Figure 4. For simplicity, we only visualize the topics mined in the first iteration of our boosting procedure. Here, we show 6 of the discovered 30 topics with their top five textual words and the five most related images, respectively. By providing a multimodal information of the representative textual and visual words, it is very intuitive to interpret the social events with each associated topic. As shown in Figure 4, the results are impressive and satisfy our expectation, where most of the extracted event topic are meaningful and textual words are well aligned with the corresponding visual image content.
B. Quantitative Evaluation
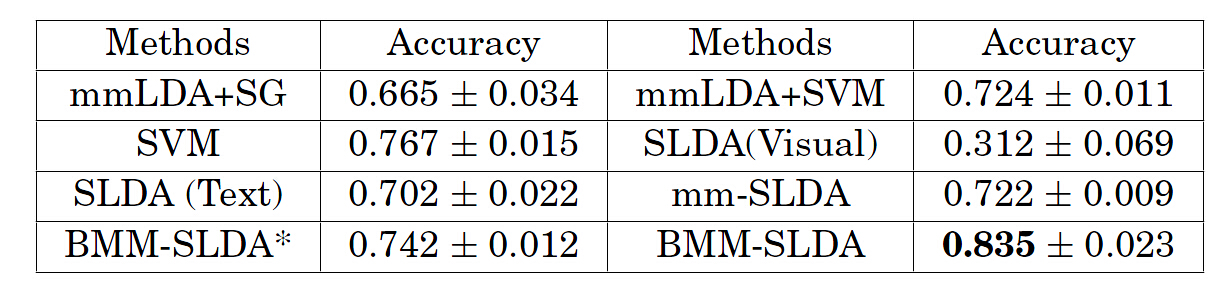
Figure 5: The social event classification accuracy compared with other existing methods on test dataset.
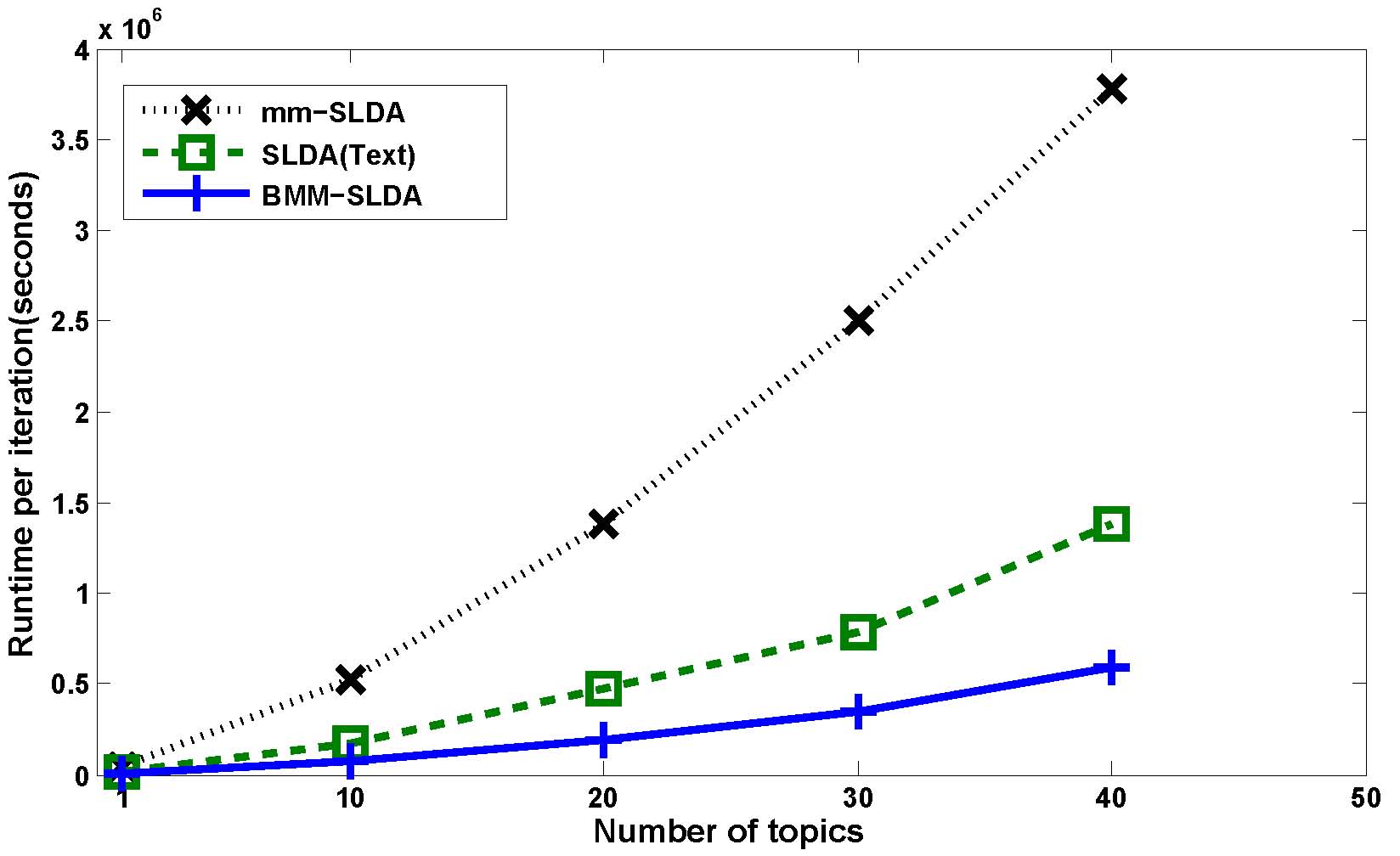
Figure 6: Comparison of computational cost of different topic models, including mm-SLDA, SLDA(Text), and BMM-SLDA.
We report the mean accuracy and its standard deviation as shown in Figure 5 (“mean ± standard deviation”). Compared with mm-SLDA, BMM-SLDA* and BMM-SLDA are much more effective and efficient on classification performance and time efficiency, respectively. In Figure 6, it shows the computational cost in each iteration process of different topic model methods on training dataset.We observe that our proposed BMM-SLDAmodel is much more efficient, which is because the training complexity per iteration is proportional to the number of documents. In our method, at each iteration of the boosting procedure, we only select a small part of documents from each category based on their weight distribution to train model while other topic models, such as SLDA(Text) and mmSLDA, train model using the entire training dataset. As a result, with the social event data growing in social media sites, the traditional topic model methods using all dataset to train model will consume unimaginable time. Different from these methods, our proposed BMM-SLDA model works on a small part of the data at each iteration and is much more efficient due to the boosting weighted sampling strategy. Therefore, our BMM-SLDA can work on a large-scale dataset. In our experiments, at each iteration of the boosting procedure, we only select 500 documents from each category based on their weight distribution. Moreover, the BMM-SLDA* and BMM-SLDA effectively model the document weight distribution with classification error, and iteratively learn new topic models to correct the previously misclassified social event documents. As a result, our BMM-SLDA* and BMM-SLDA consider the data structure and can boost the classification performance.
Publication
Social Event Classification via Boosted Multimodal Supervised Latent Dirichlet Allocation. [pdf][slides]
Shengsheng Qian, Tianzhu Zhang , Changsheng Xu and M. SHAMIM HOSSAIN
ACM Transactions on Multimedia Computing Communications and Applications (TOMM), 2014, 11 (2): Article No.: 27.