|
自然语言处理研究小组
Research Group of Natural Language Processing
自然语言处理是利用计算机技术处理人类自然语言的一门交叉型学科,涉及计算机科学、数学、逻辑学、语言学和认知科学等多个领域。模式识别国家重点实验室自然语言处理组主要从事自然语言处理基础、机器翻译、信息抽取和问答系统等相关研究工作,力图在自然语言处理的理论模型和应用系统开发方面做出创新成果。目前研究组的主要方向包括:自然语言处理基础技术(汉语词语切分、句法分析、语义分析和篇章分析等)、多语言机器翻译、信息抽取(实体识别、实体关系抽取、观点挖掘等)和智能问答系统(基于知识库的问答系统、知识推理、社区问答等)。
近年来,研究组注重于自然语言处理基础理论和应用基础的相关研究,取得了一批优秀成果,承担了一系列包括国家自然科学基金项目、“973”计划课题、“863”计划项目和支撑计划项目等在内的基础研究和应用基础研究类项目,以及一批企业应用合作项目。在自然语言处理及相关领域顶级国际期刊(CL、TASLP、TKDE、JMLR、TACL、Information
Sciences、Intelligent
Systems等)和学术会议(AAAI、IJCAI、ACL、SIGIR、WWW等)上发表了一系列高水平的研究论文。2009年获得第23届亚太语言、信息与计算国际会议(PACLIC)最佳论文奖,2012年获得第一届自然语言处理与中文计算会议(NLPCC)最佳论文奖,2014年获得第25届国际计算语言学大会(COLING)最佳论文奖。获得了10余项国家发明专利。
研究组还面向国家需求致力于应用技术和实用系统的开发。其中,多语言机器翻译系统已覆盖汉语、日语、英语、德语、法语等数十种语言对,并已在国家相关部门得到实际应用。该系统在2007至2009连续三年的国际口语机器翻译评测(IWSLT)中获得多项第一名的优异成绩,并于2011年和2013年在全国机器翻译评测(CWMT)中摘获多项第一名。推荐系统于2011年获得国际数据挖掘和知识发现权威竞赛KDD-CUP全球亚军(共1297支队伍参加),并多次在国内外信息抽取和问答系统评测中(如“863”实体识别任务、NTCIR2008观点挖掘任务、QALD-3知识问答任务等)取得多项指标第一名的优异成绩。同时,研究组研发的汉语自动分词系统、词性标注和实体识别一体化工具、句法分析器、百科知识服务平台和餐馆美食问答系统等,已在中国大百科全书出版社等国家多个企事业单位得到实际应用。

图片1交互式多语言翻译系统
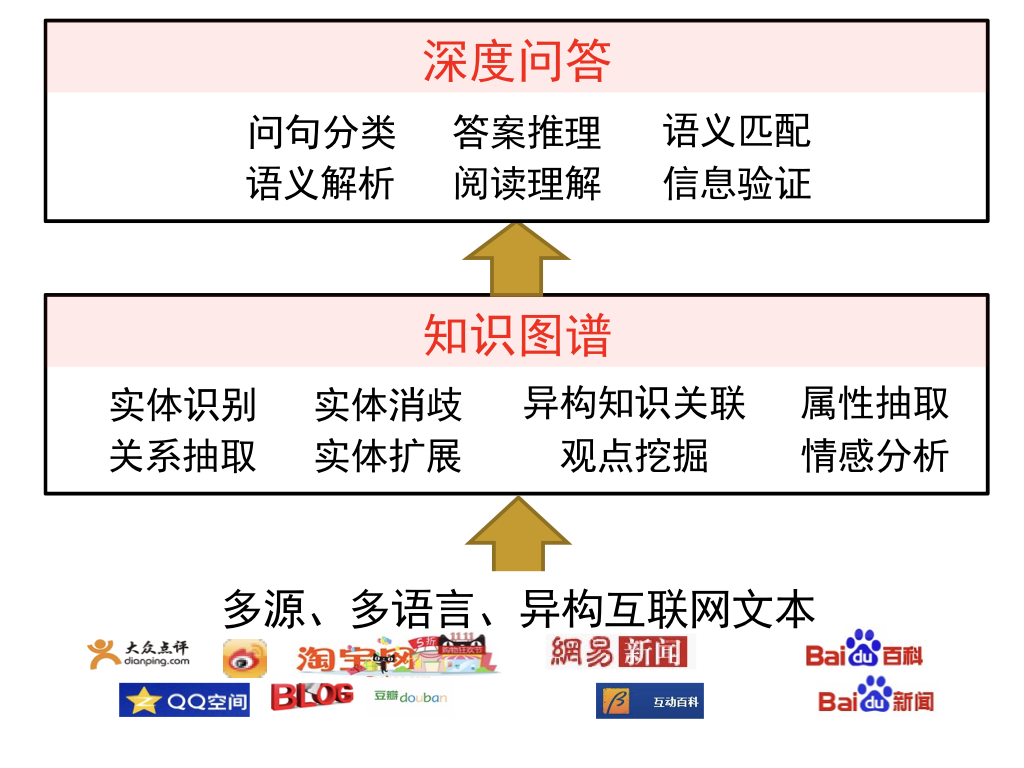
图2网络文本信息抽取与深度问答
地址:北京市海淀区中关村东路95号
电话:010-82544588 | 

